پرش به محتوا
پرش به محتوا 
گفتار از مهمترین ویژگی های صرف انسانی و همچنین مهمترین نوع ارتباط کلامی می باشد. در گفتار جریانی 3 تا 6 سیلاب به وجود می آید. این جریان تشکیل شده از اصوات مرکب که هرکدام از لحاظ فرکانسی و زمانی باهم تفاوت دارند. آواهای گفتاری هنگامی که در هجا یا کلمه، عبارت یا جمله قرار می گیرند، ویژگی های متفاوتی به خود میگیرند. در گفتار، فرکانس اصلی با تعداد تارآواها در واحد زمان مشخص می شود. تارآواهایی که در فاصله کمتری از هم قرار می گیرند، نسبت به تارآواهای دورتر، نرمتر می شوند. برای اطلاع از نحوه زبان آموزی کودکان به مقاله مرتبط مراجعه کنید.
فرکانس صوت های گفتاری همیشه مضرب صحیحی از فرکانس اصلی می باشد. صوت های گفتاری همیشه هارمونیک هستند و نمی توان ویژگی سینوسی برای آنها قائل شد. زبان، لب و دندان ها از اندام های انسانی اصوات هارمونیک را فیلتر می کنند. و برای تولید صوت های مختلف باهم مشارکت می کنند؛ و در نتیجه تغییر رزنانسی تارآواها، اصوات متفاوت ایجاد می شود.
بههمین دلیل هارمونیکهای اصلی هرفرکانس اصلی تقویت شده ودامنه هارمونیکهای کم اهمیتتر کاهش مییابد. در اثر این فیلترینگ، فرمنتهایی که با قلل اصلی طیف گفتار ارتباط دارند، تشدید می شوند. بنابراین صوت های گفتاری به وسیله طیف فرکانسی فرمانت اول، دوم و یا سوم مشخص می شوند.

واکه در گفتار
به اصوات پریودیک گفتار که در لحظاتی از زمان، انرزس یکنواختی در طیف صوتی توزیع می کنند، واکه می گویند. واکه ها شدیدترین و پایین ترین فرکانس یک مجموعه صوتی را به وجود می آورند. همچنین زیرو بمی صدا و یا طنین صدا به وسیله واکه ها دریافت می شود.
همخوان در گفتار
برخلاف واکه، به صوت های غیرپریودیک که در طیف فرکانسی وسیع و زمان بسیار کوتاه تولید می شوند، همخوان میگویند. همخوان ها از نظر مکانسیم تولید بصورت سایشی و یا انفجاری هستند. و به عنوان صوت های ناپایدار و غیرمدوله به حساب می آیند. تفاوت و درک گفتار نیز بر عهده همخوانهاست.
فرمانت در گفتار
به دلیل ارتعاش تارآواها و رزنانس اندامهای تولیدی انسانی ،قله های پرانرژی طیف گفتار به وجود می آیند. که به این قله های پرانرژی فرمانت می گویند. فرمانت ها برای درک واکه هاییکه در فرکانس همان فرمانت هستند، نقشی اساس برعهده دارند. از مهم ترین چیزها برای تشکیل و تثبیت صدای واکه، رابطه ی بین فرمانت اول و دوم می باشد.
بسامد گفتار
بسامد گفتار به نوسان های صوتی پایین یعنی در فرکانس های بین 50 تا 500 هزار گفته می شود. که هرچه گویش انسانی سریعتر باشد، تعداد بسامد ها هم بیشتر می شود. تفاوت بین واکه (بخش پریودیک) با همخوان (بخش غیرپریودیک) به وسیله بسامد درک می شود. همچنین بسامد گفتار، لحن، آهنگ، تکیه و اطلاعات آوایی را مشخص می کند.
طنین مجازی
در مجموعه های کلامی که همگی از واکه و همخوان تشکیل شده اند؛ واکه ها وظیفه انتقال زیر و بمی همخوان هایی که فرکانس بالا و شدت پایین دارند، را به عهده دارند. به نوعی می توان گفت که: حس فرکانس و طنین در همخوان هایی با شدت 50 دسی بل توسط واکه ها به وجود می آید. وقتی شدت همخوان ها در حدی کاهش می یابد که به حدود آستانه شنوایی انسان می رسد، واکه ها آنها را پوشش می دهند و دیگر نمی توان آنها را تشخیص داد.
در یک مجموعه که ترکیبی از واکه و همخوان است،به حس فرکانس و زیر و بمی تولید شده،طنین مجازی میگویند. طنین مجازی حاصل یک فرآیند پردازش مغزی است که بخاطر حافظه شنوایی و مشارکت قشر شنوایی ایجاد می شود. در این فرآیند بسیار پویای مغز، تمام اصوات صوتی دریافتی از مسیر صعودی شنوایی، کدگذاری می شوند. جالب است بدانید که حداقل سرعت این فرآیند به 2000 کد در ثانیه می رسد.
آنالیز منبع شنوایی و گفتار
آنالیز منبع شنوایی نوعی پردازش است که در طی مراحل آن، سیستم شنوایی، اجزای تشکیل دهنده صوت های مرکب را تجزیه و ترکیب می کند و به درک معنایی از منابع محیطی تولید کننده صوت می رسد. پایه و اساس شنوایی بر آنالیز منبع شنوایی استوار است. اگر در آنالیز منبع شنوایی اختلالی به وجود آید، این اختلال باعث بروز مشکلاتی در شنوایی می شود. و در ادامه اختلال درک گفتار در حضور نویز زمینه برای افرادی که مبتلا به پیرگوشی هستند یا ضایعات زبانی خاص دارند، در ارتباط با آنالیز منبع شنوایی به وجود می آید.
برخی از اصوات که منابع فضایی مختلف تولید می شوند، از لحاظ فرکانسی و زمانی متفاوت و از نظر ماهیت آکوستیک نیز منابع مختلفی دارند، به همین خاطر مغز نیز آنها را تحت عنوان وقایع صوتی متفاوت درک می کند.
در نقطه مقابل این اصوات، صوتهای هارمونیک قرار می گیرند. اصوات هارمونیک شدت افزایش و یا کاهش هماهنگی دارند و ازنظر ساختار آکوستیک، از یک منبع نشات می گیرند. مغز نیز هنگام طبقه بندی ادراکی این اصوات را در یک گروه قرار می دهد. و در اصطلاح به این اصوات، مدوله می گویند.
ادراک شنوایی همزمان، متوالی و هدفمند
پردازش تجزیه و ترکیب ادراک شنوایی و یا آنالیز منبع شنوایی به سه بخش همزمان، متوالی و هدفمند تقسیم میشود. ادراک شنوایی همزمان و متوالی، مکانیسم نوروفیزیولوژیک اتوماتیک و اولیه دارند و به یادگیری وتوجه وابستگی ندارند. این نوع ادراک شنوایی در سطح پردازشی پایین تری قرار می گیرند که در حیوانات نیز مشاهده می شود. همچنین ادراک شنوایی همزمان و متوالی ، تحت کنترل مکانیسمهای پیش توجهی و یادگیری منفعل قرار می گیرند.
پردازش شنوایی هدفمند به رهبری قشر گریز و چرخه فعال عملکرد ساختمانهای قشری و تحت قشری قرار دارد. و اساس و پایه سازمان بندی ادراک شنیداری هدفمند را به وجود می آورد. در این نوع آنالیز، یادگیری اولیه ، تعامل فعال فعالیتهای توجهی و پردازهای دیگر قشر گریز در پایین ترین گروه فعالیت های پیش توجهی ساختمانهای تحت قشری لازم می باشد.
تجزیه بستر شنوایی
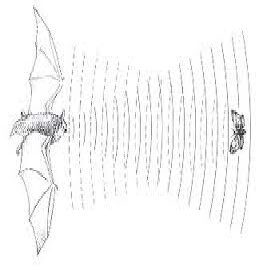
تجزیه بستر شنوایی شامل سازمان بندی ادراکی عناصر صوتی متوالی است که بستر شنوایی را به عنوان یک جریان صوتی و براساس تجزیه اجزای مولد آن بازنمایی می کند و یکی از مهمترین روش ها در آنالیز منبع شنوایی محسوب می شود. خفاش، ماهی، میمون و نوزاد انسان از تجزیه بستر شنوایی استفاده می کنند.
برخی ها در مدل نظری تجزیه بستر شنوایی اینطور می گویند که سازمانبندی ادراکی عناصر متوالی بخاطر تفاوت طیف صوتهایی که در بستر شنیداری روان هستند،به وجود میآید.
هرچند این افراد معتقدند دیگر ابعاد آکوستیک نیز تاحدودی در این امر تاثیرگذارند. الگوی زمانی صوت های وقایع آکوستیک توسط نرون های قشر شنوایی بازنمایی می شوند. مخصوصا اینکه با همزمانی زیادی به نقطه شروع صوت ها وابستگی دارند.

قشر مغزی و فعالیت نرون ها
قشر مغزی زمانی که دو بستر مختلف شنوایی را درک می کند، مطمئنا فعالیت بیشتری دارد. نرون های قشر مغزی در یک شرایط مطلوب زمانی که می خواهند یک بستر شنوایی واحد را ادراک کنند، به تمام فرکانس های اصلی و فرعی پاسخ می دهند.
این درحالی است که نرون ها در همان شرایط مطلوب، برای ادراک دو بستر شنوایی متفاوت تنها به فرکانس های اصلی پاسخ می دهند. رهبری نرون ها بر عهده قشر شنوایی می باشد. بطوریکه قشر شنوایی تمام فعالیت نرون ها را در یک نوع استراتژی کدگذاری می کند.
در یک بستر صوتی با صوت های مختلف ، اگر فرکانس های اصلی یک صوت بر فرکانس های غیر اصلی صوت دیگر مقدم باشند، قشر مغزی پاسخ کوچکتری نسبت به زمانی که فرکانس های غیر اصلی مقدم باشند، می دهد. باتوجه به مطالب گفته شده، قشر مغزی از یک الگوی متضاد برای پاسخ به فرکانس های اصلی و غیر اصلی استفاده می کند. قشر مغزی مهار فرکانسی بزرگتری برای تقدم فرکانس های اصلی برغیر اصلی ایجاد می کند.
قشر مغزی و نقشه تونوتوپیک
به وسیله نقشه تونوتوپیک می توان مهار افتراقی بزرگتر قشر مغزی در پاسخ به فرکانس های اصلی مقدم را توضیح داد. تجزیه بستر صوتی، تفاوت پاسخ های قشر شنوایی اولیه به فرکانس های اصلی و غیر اصلی که در یک محیط آکوستیک به وجود می آیند، است. بنابراین در یکی از مدلهای تجزیه بستر صوتی می توان توضیح داد که چگونه مهار افتراقی پاسخ قشر مغز به فرکانس های اصلی که بر فرکانس های غیر اصلی تقدم دارند، تحت تاثیر فعالیت عصبی نرون های موجود در منطقه تونوتوپیک قشر شنوایی اولیه، امکان تجزیه صوت ها را افزایش می دهد.
ویژگی انتخاب فرکانسی وپوشش مقدم نرونهای قشر شنوایی اولیه در بسترهای ادراکی خاص که نیازمند توجه برای ادراک صوتی تسهیل میگردد. توجه انتخابی می تواند در فرکانس های صوتی فرآیند پردازش را تقویت کند و برعکس در فرکانس هایی که در حیطه توجه انتخابی موجود نیستند، فرآیند پردازش تضعیف شود.
تغییرات زمانی درالگوی پاسخ عصبی تجزیهء بسترصوتی به ساختارادراکی شنوندگان هرمحیط وابسته است. پاسخی که توسط نرونهای قشرمغزبه فرکانسهای اصلی مقدم برفرکانس غیراصلی ارائه می شود، در یک دورهء تداوم صوتی 10ثانیه ای که نشانگر ایجاد تطابق عصبی است، کاهش می یابد. درحالیکه این تطابق نسبت به فرکانسهای غیراصلی مقدم برفرکانس اصلی کمتراست.
تولید شنوایی | توهم پیوستگی
توهم شنوایی یا استقرار شنیداری، پدیده ای دیگر با مکانیسمی مشابه تجزیه بستر صوتی می باشد. در طی این پدیده ادراک کاذب رخ می دهد، بدین صورت که مغز بصورت خودکار نقاط سکوت در یک صوت منقطع را به یک صوت شنیداری پیوسته تبدیل می کند.
در وضعیت توهم شنوایی قشر شنوایی، صوت های منقطعی که با فاصله های کمتر از 20 میلی ثانیه تولید می شوند، را یک واقعه آکوستیک ممتد استنتاج می کند. از پدیده توهم شنوایی این نتیجه حاصل می شود که قشر مغزی دارای پتانسیل بالقوه ای است که لحظات فقدان تحریک را بطور خودکار ترمیم می کند.
توهم پیوستگی و غیرهمزمانی
قشر شنوایی در پدیده غیرهمزمانی دو صوت مختلف را در یک یا دو بستر صوتی افتراق می دهد. این بدان معناست که مغز برای درک اختلاف بین دو پدیده صوتی حداقل فاصله زمانی حدود 20 تا 40 میلی ثانیه از زمان شروع تا خاتمه صوت ها را نیاز دارد. در نتیجه اگر فاصله سکوت بین دو تحریک صوتی از 20 میلی ثانیه کمتر باشد، نرون های قشر شنوایی نمی توانند بین دو پدیده صوتی تمایز قائل شوند و آن جریان صوتی را به عنوان یک واقعه صوتی درک می کنند.
به همین صورت در مورد سیلابهای گفتاری اگر زمان شروع صدا یا فاصله بین خروج هوا از دهان و تولید صدای واکه کمتر از 20 میلی ثانیه باشد، قشر مغزی برای درک سیلاب ها دچار اختلال می شوند. با توجه به مفاهیم گفته شده، آستانه ادراک افتراق برای ایجاد ناهمزمانی و ادراک دو صوت گفتاری متفاوت برابر با 20 میلی ثانیه می باشد.
در مورد اطلاعات فضایی یک منبع صوتی که منتشر می شوند، به دلیل انکسار، شکست، انعکاس و ارتعاشات مکرر اصوات در محیط، مغشوش می شوند و اعتبار چندانی ندارند. درحالیکه اطلاعات زمانی اصواتی که بصورت همزمان یا غیرهمزمان دریافت می شوند، اطلاعات ارزشمندی برای تعیین منبع مولد صوت و آنالیز منبع صدا محسوب می شوند.